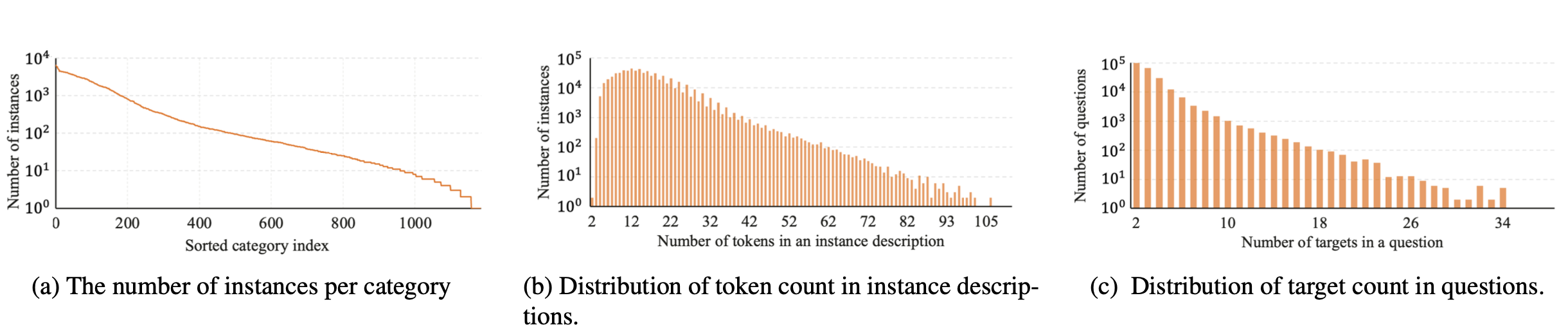
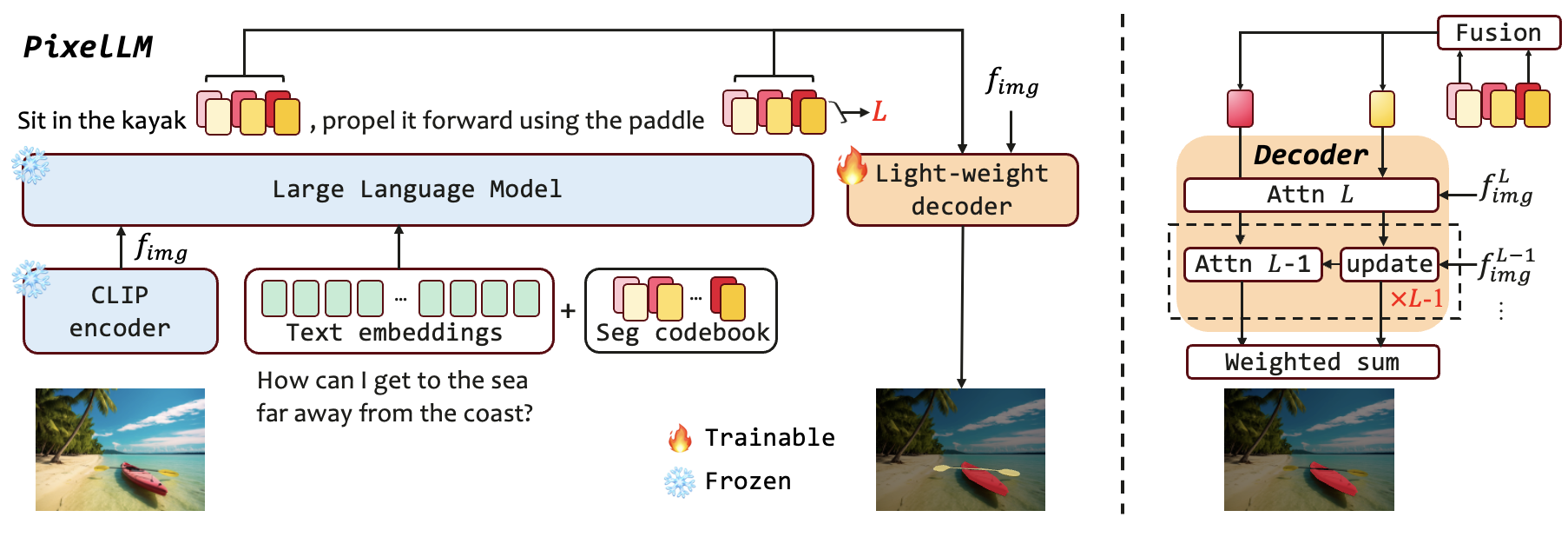
Segmentation codebook
Specifically, the codebook consists of multiple token groups, each corresponding to a semantic scale of visual features from the image encoder. Formally, we define \(C_{\text{seg}} = \left\{ c_n^{\ell} \in \mathbb{R}^d \right\}_{n=1,\ell=1}^{N,L}\), where \(L\) and \(N\) denote the number of visual scales and tokens per group, respectively, and \(d\) represents the hidden dimension in LMMs. For clarity, we first set \(N=1\) and expound on how the codebook tokens are integrated within the LMMs to encode requisite information for target mask generation.
For an input image \(x_{\text{img}}\), the vision encoder \(\mathcal{I}\) extracts a spectrum of multi-scale visual features \(I_{\text{img}} = \{ I_{\text{img}}^{\ell} \}_{\ell=1}^{L}\) from \(\mathcal{I}(x_{\text{img}})\), comprising \(L\) visual features output at select layers of \(\mathcal{I}\). The output of the final layer, \(I_{\text{img}}^{L}\), encapsulates global image information and is transformed into the language space via a vision-to-language projection layer \(p_{V\rightarrow T}\). Simultaneously, a vision-to-decoder projection \(p_{V\rightarrow D}\) transforms all \(I_{\text{img}}\) features, resulting in \(f_{\text{img}} = \left\{f_{\text{img}}^{\ell}=p_{V\rightarrow D}(I_{\text{img}}^{\ell})\right\}_{\ell=1}^{L}\). The codebook tokens, combined with the input image and text, are then processed by the LLM to generate interleaved response \(y_{\text{res}}\) in an auto-regressive way: \begin{equation*} y_{\text{res}}=\mathcal{F}(p_{V\rightarrow T}(I_{\text{img}}^{L}),x_{\text{txt}}, C_{\text{seg}}). \end{equation*} To help understand this process, consider an example of text query ''Segment the apple on the left''. Then, the output \(y_{\text{res}}\) contains \(L\) tokens of \(C_{\text{seg}}\): '' The apple is \(c^1,\dots,c^L\)''. The corresponding hidden embeddings (i.e. the output of last layer of \(\mathcal{F}\)) of \(C_{\text{seg}}\) are represented as \(h=\left\{h^{\ell}\right\}_{\ell=1}^{L}\), which are inputs to the pixel decoder \(\mathcal{D}\) alongside image features \(f_{\text{img}}\) for mask generation. Each token interacts with the image feature at its corresponding scale.
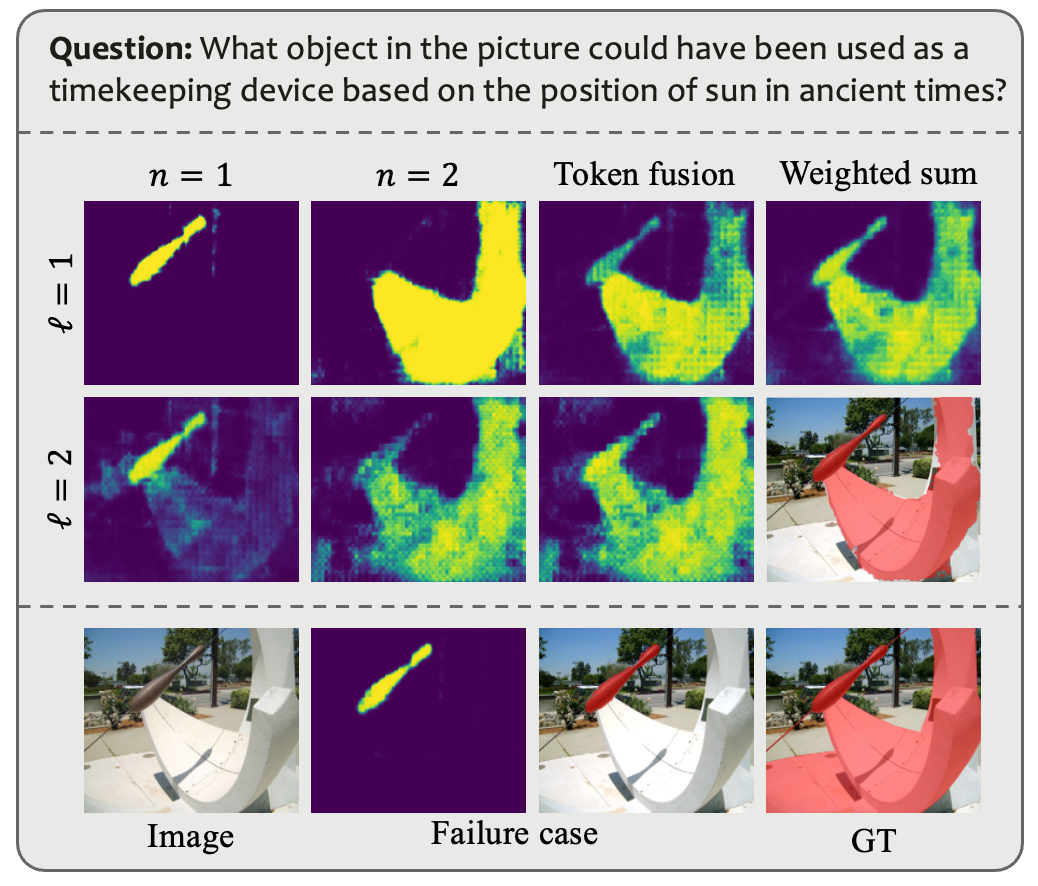
We then set \(N>1\) and explain the rationale. As shown in the upper right figure, scenarios featuring multiple targets or inherent complexity challenge the capacity of a single token to fully encapsulate target semantics, even though the LLM can provide accurate textual responses. In the figure, the segmentation codebook example comprises two scales with two tokens each. Each attention map results from the interaction between one token and its corresponding image feature in the decoder. The first two rows depict the token fusion mechanism, while the final row demonstrates a failure case arising from the utilization of only one token.
To enhance the model's interpretative ability in complex reasoning scenarios, we propose a token fusion mechanism that utilizes multiple tokens within each scale group, i.e. \(c^{\ell} = \left\{c_n^{\ell}\right\}_{n=1}^N\). Prior to decoder, a linear projection layer \(\phi\) is employed to transform the hidden states of grouped tokens into \(h^{\ell}=\phi(h_1^{\ell},\dots,h_N^{\ell})\). The figure illustrates the utilization of multiple tokens per group. The visualization of each attention map post decoder reveals that disparate tokens yield complementary information, culminating in enhanced mask compared to a single token setting.